LMCache
综合介绍
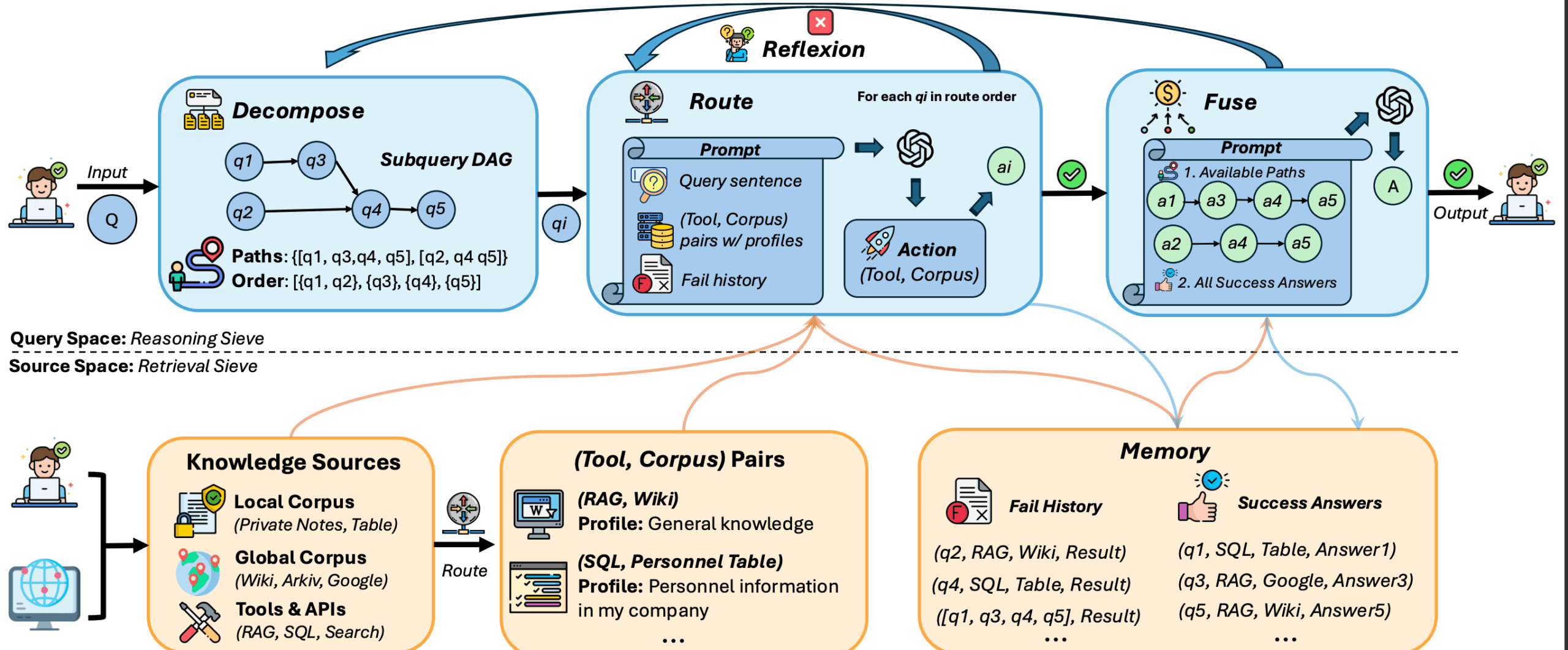
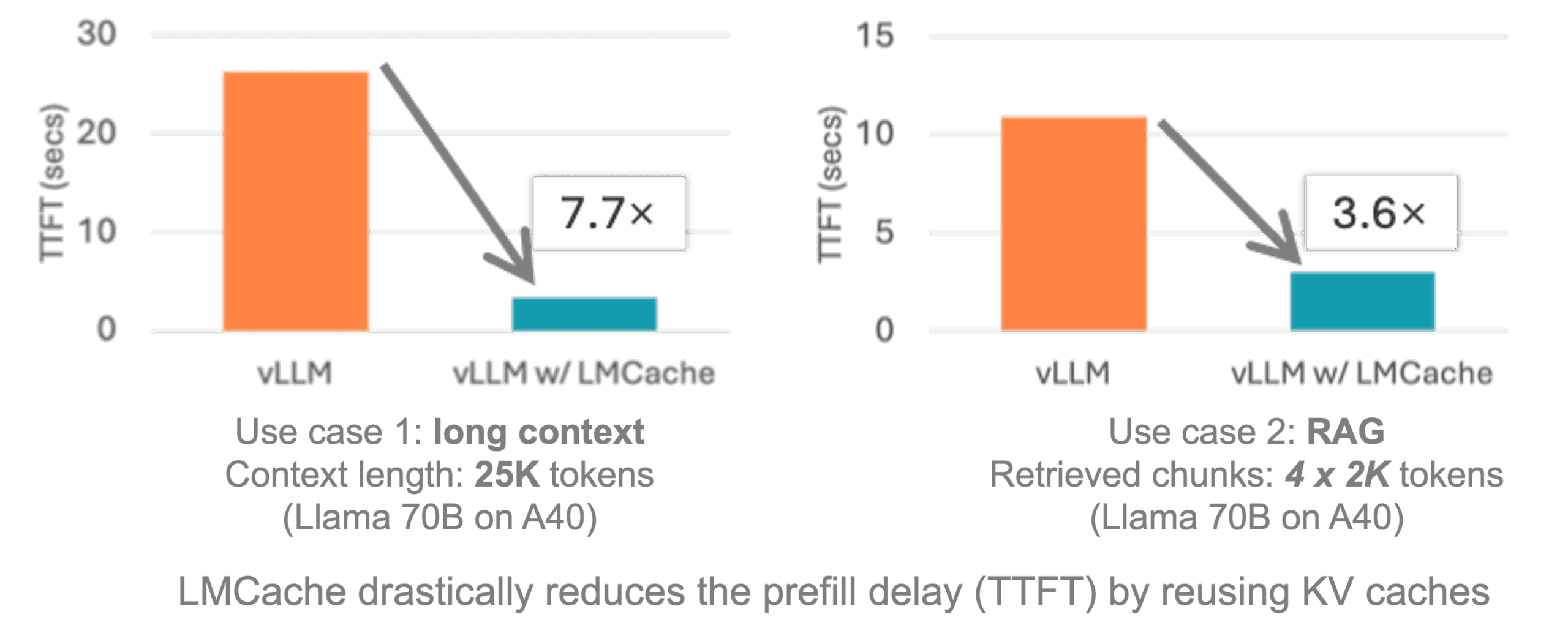
LMCache是一个开源的、为大语言模型(LLM)推理服务设计的扩展加速层。 它的核心工作原理是缓存和复用模型在处理文本时产生的键值对(KV Cache)。在LLM进行文本生成时,注意力机制需要为每个输入词元(token)计算键(K)和值(V)向量,这个过程非常消耗计算资源。LMCache通过将这些计算结果存储在包括GPU显存、CPU内存和本地磁盘在内的多级存储中,使得当同样内容的文本再次出现时,系统可以直接读取缓存,跳过重复计算。 这种机制不仅限于文本前缀的复用,而是能识别并利用任意位置出现的重复文本块。 LMCache与vLLM等主流推理框架集成,能显著降低长篇文档处理、多轮问答和检索增强生成(RAG)等场景下的首次响应时间(TTFT),并提升系统的整体吞吐量,从而节省GPU资源并改善用户体验。
功能列表
- 与vLLM集成:无缝对接vLLM推理框架,充分利用其高性能特性。
- 多级缓存存储:支持将KV缓存智能地存储在GPU显存、CPU内存和本地磁盘上,并根据性能需求动态调度。
- 非前缀缓存复用:能够识别并复用请求中任意位置出现的重复文本片段,而不仅仅是开头部分。
- 跨实例缓存共享:通过P2P缓存共享机制,允许多个独立的vLLM服务实例之间共享和复用缓存内容。
- CPU缓存卸载:具备高性能的CPU缓存卸载功能,能将不常用的缓存从昂贵的GPU显存转移到CPU内存中。
- 支持多种后端:除了本地存储,还可以与Redis等外部实时数据库集成,作为大规模部署环境下的缓存后端。
使用帮助
LMCache的设计目标是简化使用流程,让开发者能以最小的改动为现有的大模型推理服务带来性能提升。
核心概念:什么是KV Cache?
在理解LMCache之前,需要先了解它所操作的对象:KV Cache(键值缓存)。在Transformer架构的大语言模型中,自注意力(Self-Attention)机制是其核心。模型在生成每一个新的词元时,都需要回顾并处理之前已经生成或提供的所有词元序列。
为了避免每次都从头计算整个序列,模型会将序列中每个词元的“键(Key)”和“值(Value)”向量缓存起来。当生成下一个词元时,模型只需要为当前这一个新词元计算查询(Query)向量,然后与缓存中所有历史词元的“键”和“值”进行运算即可。这个存储历史“键”和“值”的区域就是KV Cache。
对于长文本或多轮对话,KV Cache会变得非常大,管理和重用它就成了提升效率的关键。LMCache正是为了解决这个问题而生,它将这份宝贵的计算结果持久化并跨请求共享。
安装
LMCache可以通过Python的包管理器pip直接安装。环境需要Python 3.10以上版本和CUDA 12.1以上的环境。
pip install lmcache
快速上手:在vLLM中使用LMCache
LMCache与vLLM的集成非常紧密。启动一个兼容OpenAI API的vLLM服务并加载LMCache,只需要在启动命令前加上lmcache_vllm。
启动服务
例如,要启动一个使用lmsys/longchat-7b-16k模型的服务,并开启LMCache,可以使用以下命令:
lmcache_vllm serve lmsys/longchat-7b-16k --gpu-memory-utilization 0.8
这条命令会启动一个HTTP服务器。LMCache会自动接管底层的KV缓存管理。当服务器接收到多个包含相同内容片段的请求时(例如,多个用户都在使用相同的系统提示或查询相似的文档),LMCache会自动进行缓存和复用,从而加速响应。
离线推理
在进行离线批处理任务时,只需在导入vLLM库之前导入lmcache_vllm即可。
# 导入lmcache_vllm来启用缓存功能
import lmcache_vllm.vllm as vllm
from lmcache_vllm.vllm import LLM, SamplingParams
# 像往常一样初始化LLM模型
# LMCache会在后台自动管理KV缓存
llm = LLM(model="lmsys/longchat-7b-16k")
prompts = [
"请详细介绍一下爱因斯坦的相对论。",
"爱因斯坦的相对论对现代物理学有哪些深远的影响?",
]
sampling_params = SamplingParams(temperature=0.7, top_p=0.95, max_tokens=500)
# 第一次生成时,LMCache会缓存提示中的通用部分
outputs = llm.generate(prompts, sampling_params)
# 打印输出
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"提示: {prompt}")
print(f"生成内容: {generated_text}\n")
在以上代码中,虽然看起来和普通的vLLM调用没有区别,但lmcache_vllm的导入已经激活了缓存系统。当处理包含重叠上下文的批量提示时,性能会有明显提升。
进阶用法:跨实例共享缓存
在生产环境中,通常会部署多个模型推理服务实例来应对高并发。LMCache支持在这些不同实例之间共享KV缓存,最大化缓存的利用率。
第一步:启动LMCache中心服务器首先,需要启动一个独立的lmcache_server进程,它将作为所有服务实例的缓存协调和存储中心。
lmcache_server localhost 65432
这会在本地的65432端口启动一个缓存服务器。
第二步:配置并启动vLLM实例然后,需要创建一个配置文件(例如cache_config.yaml),告诉vLLM实例如何连接到缓存服务器。
# cache_config.yaml
remote_server_addr: "localhost:65432"```
最后,在启动vLLM服务实例时,通过环境变量指定该配置文件。你可以启动多个实例,它们都会连接到同一个缓存服务器。
**实例1:**
```bash
LMCACHE_CONFIG_FILE=cache_config.yaml CUDA_VISIBLE_DEVICES=0 lmcache_vllm serve lmsys/longchat-7b-16k --port 8000
实例2:
LMCACHE_CONFIG_FILE=cache_config.yaml CUDA_VISIBLE_DEVICES=1 lmcache_vllm serve lmsys/longchat-7b-16k --port 8001
现在,发送到8000端口的请求所产生的缓存,可以被8001端口的请求复用,反之亦然。这对于需要处理大量相似请求的RAG系统或大型问答平台尤其有效。
应用场景
- 检索增强生成(RAG)在RAG应用中,系统会先从知识库中检索相关文档片段,然后将这些片段作为上下文连同用户问题一起提交给大模型。当多个用户查询到相同的热门文档时,LMCache可以缓存这些文档的KV Cache,避免为每个查询重复计算,从而大幅降低延迟和成本。
- 多轮对话机器人在持续的对话中,每一轮都需要将之前的对话历史作为上下文。LMCache可以缓存前面几轮对话的KV Cache。当用户发出新一轮请求时,模型只需处理最新的内容,显著加快响应速度,改善交互体验。
- 长文档分析与摘要当用户需要对一篇长文档进行多次提问或生成摘要时,整个文档的KV Cache可以被一次性计算并缓存。后续所有基于该文档的操作都可以直接复用缓存,使得交互几乎是瞬时的。
- 代码辅助生成在代码生成或补全任务中,许多代码片段(如导入的库、通用函数定义、类结构)会频繁出现。LMCache可以缓存这些通用代码的KV Cache,当开发者在不同文件中编写相似代码时,系统能更快地提供代码建议。
QA
- LMCache和vLLM自带的PagedAttention有什么不同?它们是互补的技术。PagedAttention是一种高效的显存管理技术,它在单个请求的生命周期内,通过分页机制灵活管理KV Cache,避免了显存碎片化。而LMCache是一个更高层级的、跨请求甚至跨实例的缓存系统。它负责将PagedAttention管理的KV Cache进行持久化存储和共享,使得不同请求之间可以复用计算结果。简单来说,PagedAttention优化“单个请求内”的缓存管理,LMCache优化“多个请求间”的缓存复用。
- LMCache支持哪些大语言模型?由于LMCache是作为vLLM等推理引擎的扩展工作的,它理论上支持所有vLLM支持的模型,例如Llama系列、Mixtral、Qwen、ChatGLM等。只要模型可以在vLLM上运行,就可以通过LMCache来获得加速。
- 使用LMCache需要多大的缓存空间?所需空间取决于具体的应用场景、模型大小、上下文长度和预期的缓存命中率。LMCache的优势在于其分层存储机制。你可以将最常用、对延迟最敏感的缓存放在GPU显存中,将次级缓存放在成本更低的CPU内存中,甚至将海量的、不常用的缓存放在磁盘上。这种灵活性允许用户根据自己的硬件预算和性能目标进行权衡和配置。